Despre standardul UTF-8 și limbajul Python
Ce este UTF-8?
UTF-8 sau
Unicode Transformation Format 8-bit, este o metodă ingenioasă de a reprezenta caracterele din
toate limbile lumii folosind numere și biți. Înainte de
UTF-8, programatorii se confruntau cu provocarea de a gestiona
diferite seturi de caractere pentru fiecare limbă. Dar acum, putem să punem împreună toate aceste caractere
diverse într-o singură bucată de cod.
 De ce este Important?
De ce este Important? Imaginați-vă că dezvoltați o aplicație care să fie utilizată în întreaga lume.
Oamenii din diverse țări vor dori să folosească aplicația voastră și să introducă text în limba lor maternă.
UTF-8 vă permite să faceți acest lucru fără a vă face griji că textul introdus va fi interpretat greșit
sau că unele caractere nu vor putea fi afișate corect.
Cum lucrăm cu UTF-8 în Python?
În Python, lucrurile sunt surprinzător de simple. Atunci când lucrați cu șiruri de caractere, Python vă permite
să folosiți caracterele
UTF-8 direct. De exemplu, puteți defini un șir de caractere cu litere din diverse limbi,
și Python le va trata fără probleme:
text = "Привет, Hello, 你好!"
print(text)
Acest cod va afișa corect toate caracterele, indiferent de limba din care provin. Chiar și acest fișier
HTML respectă
acest standard, deci caracterele au putut fi afișate imediat în pagină.
De asemenea, puteți să vă asigurați că fișierele dvs. Python sunt în formatul
UTF-8 prin adăugarea unui comentariu
la începutul fișierului:
# -*- coding: utf-8 -*-
Dacă dorim să introducem în Python simbolul de drepturi de autor (
©) folosind codul său
Unicode,
vom tasta următoarele:
sir = '\u00A9'
print(sir)
Mai sus am creat un șir de caractere folosind codul
Unicode "
\u00A9". Deoarece șirul de caractere Python
utilizează codificarea
UTF-8 în mod implicit, afișarea valorii lui
sir se schimbă automat în mod
corespunzător în simbolul Unicode. Observați că secvența "
\u" de la începutul unui punct de
cod este necesară. Fără ea, Python nu va putea converti punctul de cod.
Lista caracterelor UTF-8
https://home.unicode.org/
Mai multe detalii
UTF-8 este un standard de codificare a caracterelor folosit în informatică pentru a reprezenta textul în
limbajele umane. Acest standard are rolul de a asocia fiecărui caracter (literă, cifră, semn de punctuație,
simbol etc.) cu o secvență unică de biți (
0 și
1), permițând astfel calculatoarelor să înțeleagă
și să afișeze diverse limbaje și simboluri din întreaga lume.
UTF-8 utilizează o schemă de codificare variabilă, ceea ce înseamnă că caracterele sunt reprezentate
folosind un număr variabil de biți, în funcție de caracter. Caracterele comune (precum literele din
alfabetul englez) sunt reprezentate folosind un număr mai mic de biți, în timp ce caracterele mai rare
sau mai complexe (precum literele din limbi cu scriere non-latină) sunt reprezentate folosind un
număr mai mare de biți. Acest lucru face ca
UTF-8 să fie eficient din punct de vedere al spațiului
și să poată reprezenta o gamă largă de caractere.
De exemplu, să luăm litera "
A". În codul
Unicode, aceasta are un punct de cod numeric, în acest caz,
"
U+0041". În reprezentarea
UTF-8, această literă este codificată cu secvența de biți
01000001.
Acest sistem de reprezentare permite unificarea modului în care computerele interpretează și
afișează literele, chiar dacă ele provin din diferite limbi.
Un alt punct important este că
UTF-8 nu se limitează la litere și caractere alfabetice. El poate reprezenta
simboluri matematice, emoticoane, semne de punctuație, logotipuri și multe altele. Să luăm exemplul emoji-ului
Milky Way ("🌌"), care în codul Unicode este "
U+1F604". În
UTF-8, acesta este codificat cu secvența de
biți
11110000 10011111 10001100 10001100.
De-a lungul anilor, adoptarea largă a UTF-8 în domeniul programării și pe internet a făcut posibilă comunicarea
și colaborarea globală fără a mai fi nevoie de conversii și adaptări complicate între diferite seturi de caractere.
Așadar, în lumea digitală de astăzi, cunoștințele despre UTF-8 sunt vitale pentru a crea aplicații și site-uri web
interculturale și interoperabile.
Codificarea și decodificarea șirurilor
Limbajul de programare Python oferă funcții implicite pentru
codificarea și decodificarea șirurilor de caractere.
Spre exemplu, funcția
encode() convertește (
codifică) un șir de caractere într-un șir de octeți:
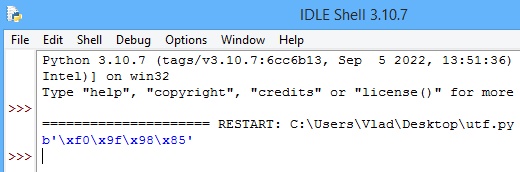
emoji = '😅'
print(emoji.encode('utf-8'))
Rezultatul în consolă este următorul:
 Să detaliem puțin
Să detaliem puțin. Expresia afișată reprezintă o secvență de octeți în formatul codificării UTF-8,
care este o modalitate comună de a reprezenta caractere Unicode în formă binară:
\xf0 (în binar, "11110000")
Acest octet face parte dintr-o secvență de mai mulți octeți care reprezintă un caracter Unicode.
Este un octet de început care indică că urmează o secvență mai lungă pentru reprezentarea caracterului.
\x9f ("10011111")
Al doilea octet din secvența și face parte din codul Unicode al caracterului.
\x98 ("10011000")
Al treilea octet din secvență și face parte tot din codul Unicode al caracterului.
\x85 ("10000101")
Ultimul octet din secvență și face parte, de asemenea, din codul Unicode al caracterului.
Așadar, emojiul se poate scrie pe biți (4 octeți) astfel: "
11110000 10011111 10011000 10000101".
Prefixul "
b" din expresie indică faptul că această secvență de caractere este un șir de octeți (8 biți).
Vezi mai multe caractere exprimate astfel [
aici].
Similar,
decodificarea se realizează cu ajutorul funcției
decode():
binar = b'\xf0\x9f\x8c\x8d'
print(binar.decode('utf-8'))
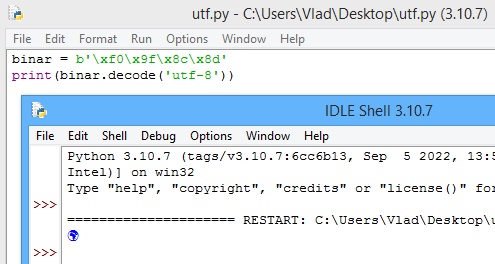
În consolă a fost afișat caracterul corespunzător (emoji-ul "
Earth Globe Europe-Africa").
Hai și tu în clubul nostru!
Python 3 e super tare!




